




elasticsearch安装
下载
下载地址:https://www.elastic.co/cn/downloads/elasticsearch
说明:本教程只是安装教程,理论上7.x版本都支持,安全确保系统干净
由于本教程发布时集成springboot的版本还没上来,为确保可以集成springboot,请安装es-7.9.3版本,目前springboot集成的最新的版本
上传服务器
解压
tar -zxvf elasticsearch-7.10.1-linux-x86_64.tar.gz
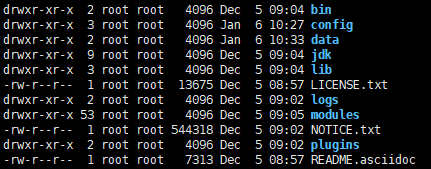
drwxr-xr-x 2 root root 4096 Dec 5 09:04 bin
drwxr-xr-x 3 root root 4096 Jan 6 10:27 config //配置文件
drwxr-xr-x 2 root root 4096 Jan 6 10:33 data //解压没有当前文件夹,自己创建
drwxr-xr-x 9 root root 4096 Dec 5 09:04 jdk //es的java环境
drwxr-xr-x 3 root root 4096 Dec 5 09:04 lib //jar包依赖
-rw-r--r-- 1 root root 13675 Dec 5 08:57 LICENSE.txt
drwxr-xr-x 2 root root 4096 Dec 5 09:02 logs //日志文件
drwxr-xr-x 53 root root 4096 Dec 5 09:05 modules //es的模块
-rw-r--r-- 1 root root 544318 Dec 5 09:02 NOTICE.txt
drwxr-xr-x 2 root root 4096 Dec 5 09:02 plugins //es的扩展文件
-rw-r--r-- 1 root root 7313 Dec 5 08:57 README.asciidoc
配置
进入到config文件夹,
-rw-rw---- 1 root root 2831 Dec 5 08:57 elasticsearch.yml
-rw-rw---- 1 root root 2301 Dec 5 08:57 jvm.options
drwxr-x--- 2 root root 4096 Dec 5 09:02 jvm.options.d
-rw-rw---- 1 root root 18185 Dec 5 09:02 log4j2.properties
-rw-rw---- 1 root root 473 Dec 5 09:02 role_mapping.yml
-rw-rw---- 1 root root 197 Dec 5 09:02 roles.yml
-rw-rw---- 1 root root 0 Dec 5 09:02 users
-rw-rw---- 1 root root 0 Dec 5 09:02 users_roles
修改配置elasticsearch.yml
Paths
path.data: /usr/local/elasticsearch-7.10.1/data //后期数据存放的位置
path.logs: /usr/local/elasticsearch-7.10.1/logs //后期日志存放的位置
后期如果安装 elasticsearch head的时候,可能会引起跨域问题,在network后面加以下内容即可。
Network
http.cors.enabled: true
http.cors.allow-origin: "*"
新建用户启动
当我们修改配置文件后,进入bin目录启动,
./elasticsearch
发现启动报错
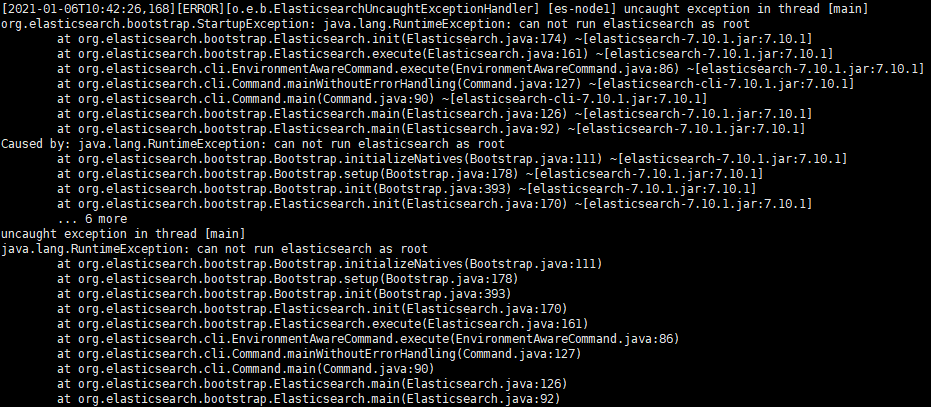
原因:
为了安全不允许使用root用户启动
useradd esuser //添加用户
chown -R esuser /usr/local/elasticsearch-7.10.1 //授权用户 后面是es的安装地址
在此启动,发现任然报错。

环境配置不足需要配置
vim /etc/security/limits.conf //修改配置文件
//添加以下内容到末尾(注意*也需要)
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
vim /etc/sysctl.conf //修改配置文件
//末尾加上
vm.max_map_count=262145
//一定记得刷新配置
sysctl -p
大功告成,启动
访问自己的 ip:8200
{
"name": "es-node1",
"cluster_name": "bearjun-es",
"cluster_uuid": "cPF5FqvsQfC1CdtJIakAOA",
"version": {
"number": "7.10.1",
"build_flavor": "default",
"build_type": "tar",
"build_hash": "1c34507e66d7db1211f66f3513706fdf548736aa",
"build_date": "2020-12-05T01:00:33.671820Z",
"build_snapshot": false,
"lucene_version": "8.7.0",
"minimum_wire_compatibility_version": "6.8.0",
"minimum_index_compatibility_version": "6.0.0-beta1"
},
"tagline": "You Know, for Search"
}
什么是分词
把文本转换为-个个的单词,分词称之为analysis. es默认只对英文语句做分词,中文不支持,每个中文字都会被所分为独立的个体。
- 英文分词:i study in bearjun.com
- 中文分词:我在bearjun博客学习
post /_analyze
{
"analyzer":"standard",
"text":"text文本"
}
post /_analyze
{
"analyzer":"standard",
"field":"name",
"text":"text文本"
}
es内置分词器
- standard:默认分词,单词会被拆分,大写转成小写
- simple:按照非字母分词,大写转成小写
- whitespace:按照空格分词,大写转小写
- stop:去除无意义单词,忽略大小写
- keyword: 不分词,把整个文本做关键词
ik中文分词器
GitHub地址:https://github.com/medcl/elasticsearch-analysis-ik
官方提供了两种分词器安装的方式,我们选择第一种
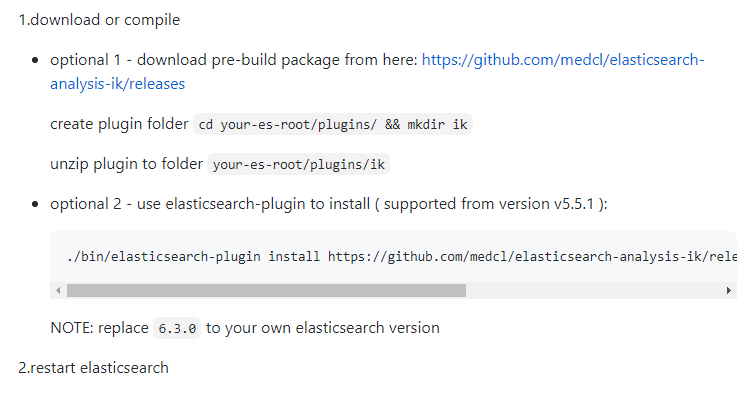
ik分词的安装
- 下载zip的安装包。(主要和es的版本保持一致)
- 上传到es/plugins/下面
- 解压分词器到当前的一个新建的文件夹下
unzip -n elasticsearch-analysis-ik-7.10.1.zip -d /usr/local/es/plugins/ik
如果没有unzip,请参考:[https://bearjun.com/index.php/linux/220.html][8]
-
切换用户,重启es
-
测试ik分词器是否可用
- ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合,适合 Term Query;
- ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”,适合 Phrase 查询。
post /_analyze { "analyzer":"ik_max_word", "text":"上下班车流量很大" } //输出结果 { "tokens": [ { "token": "上下班", "start_offset": 0, "end_offset": 3, "type": "CN_WORD", "position": 0 }, { "token": "上下", "start_offset": 0, "end_offset": 2, "type": "CN_WORD", "position": 1 }, { "token": "下班", "start_offset": 1, "end_offset": 3, "type": "CN_WORD", "position": 2 }, { "token": "班车", "start_offset": 2, "end_offset": 4, "type": "CN_WORD", "position": 3 }, { "token": "车流量", "start_offset": 3, "end_offset": 6, "type": "CN_WORD", "position": 4 }, { "token": "车流", "start_offset": 3, "end_offset": 5, "type": "CN_WORD", "position": 5 }, { "token": "流量", "start_offset": 4, "end_offset": 6, "type": "CN_WORD", "position": 6 }, { "token": "很大", "start_offset": 6, "end_offset": 8, "type": "CN_WORD", "position": 7 } ] }
自定义词库
位于/analysis-ik/config/IKAnalyzer.cfg.xml 可以自定义词库,这里不过多介绍,如果感兴趣可以留言讨论。
ElasticSearch相关名词解释
接近实时(NRT Near Real Time )
Elasticsearch是一个接近实时的搜索平台。这意味着,从索引一个文档直到这个文档能够被搜索到有一个轻微的延迟(通常是1秒内)
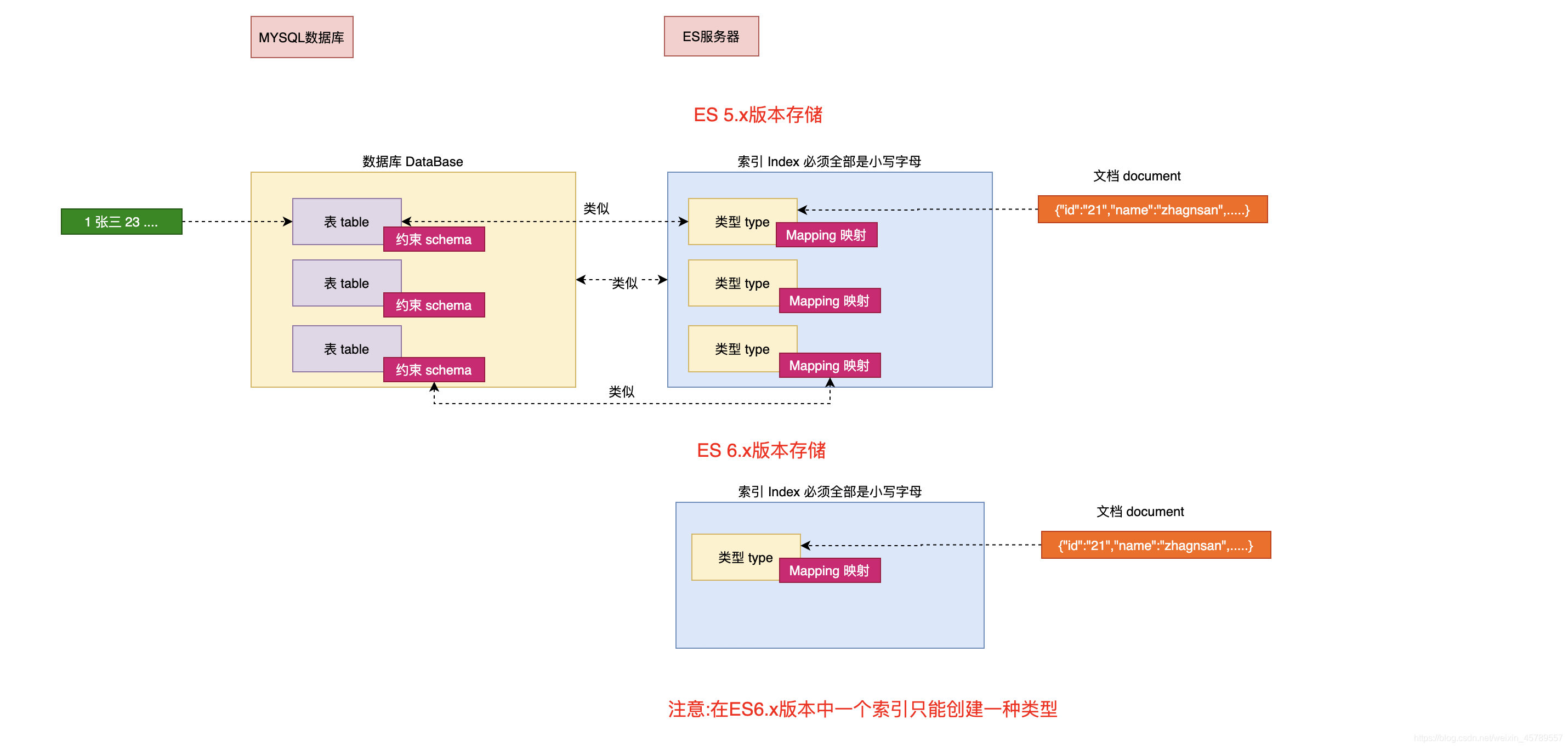
索引(index)
一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引,或者是产品目录的索引,亦或者是订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。索引类似于关系型数据库中Database 的概念。在一个集群中,如果你想,可以定义任意多的索引。
类型(type)
在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。通常,会为具有一组共同字段的文档定义一个类型。比如说,我们假设你运营一个博客平台并且将你所有的数据存储到一个索引中。在这个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,当然,也可以为评论数据定义另一个类型。类型类似于关系型数据库中Table的概念。
注意: 在5.x版本以前可以在一个索引中定义多个类型,6.x之后版本也可以使用,但是不推荐,在7~8.x版本中彻底移除一个索引中创建多个类型
映射(Mapping)
Mapping是ES中的一个很重要的内容,它类似于传统关系型数据中table的schema,用于定义一个索引(index)中的类型(type)的数据的结构。 在ES中,我们可以手动创建type(相当于table)和mapping(相关与schema),也可以采用默认创建方式。在默认配置下,ES可以根据插入的数据自动地创建type及其mapping。 mapping中主要包括字段名、字段数据类型和字段索引类型
文档(document)
一个文档是一个可被索引的基础信息单元,类似于表中的一条记录。比如,你可以拥有某一个员工的文档,也可以拥有某个商品的一个文档。文档以采用了轻量级的数据交换格式JSON(Javascript Object Notation)来表示。
关系图
评论区