



说起redis,我们熟知的基本都是以下的5种数据类型:
- String
- Hash
- List
- Set
- zSet
但是我们不常用的还有以下3种:
- bitMap
- hyperLoglog
- Geo
从官网我们可以看出:
Redis是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。它支持多种类型的数据结构,如字符串(strings),散列(hashes),列表(lists),集合(sets),有序集合(sorted sets)与范围查询,bitmaps,hyperloglogs和地理空间(geospatial)索引半径查询
官方地址:https://redis.io/
中文地址:http://redis.cn/
常用的命令地址:http://redisdoc.com/index.html
String
String类型是二进制安全的。意味着Redis的string可以包含任何数据。比如jpg图片或者序列化的对象。
String类型是Redis最基本的数据类型,一个Redis中字符串value最多可以是512M
常见用法
- set key value 赋值 / mset key value [key value ....] 一次赋值多个值
- get key 获取值 / mget key [key ....] 一次获取多个值
- incr key 对一个数值自增1 / incrby key number 对一个数值加number
- decr key 对数值自减1 / decrby key number 对一个数值减number
- setnx key value / set key value [ex seconds] [px milliseconds] [nx|xx] 设置key是否存在才存入或者设置过期时间等
## get set
bearjun:1>set string:demo1 1
"OK"
bearjun:1>get string:demo1
"1"
## mset mget
bearjun:1>mset string:demo2 2 string:demo3 3
"OK"
bearjun:1>mget string:demo2 string:demo3
1) "2"
2) "3"
## incr
bearjun:1>incr string:demo2
"3"
## decr
bearjun:1>decr string:demo3
"2"
## incrby
bearjun:1>incrby string:demo1 2
"3"
## decrby
bearjun:1>decrby string:demo1 2
"1"
## nx : string:demo1不存在才能存入
bearjun:1>setnx string:demo1 nx
"0"
bearjun:1>setnx string:demo4 4
"1"
## ex 设置过期时间
bearjun:1>set string:demo5 5 ex 100
"OK"
## ttl 获取过期时间
bearjun:1>ttl string:demo5
"81"
应用场景
- 阅读数:每次点击一次自增1。
- 分布式锁:使用setnx当key不存在的时候使用。
Hash
一个string类型的field和value的映射表,hash特别适合用于存储对象。类似Java里面的Map<String,Object>。
常见用法
- hset key field value / hmset key field value [field value ...] 赋值或者批量赋值
- hget key field / hmget key field [field ....] 取值或者批量取值
- hgetall key 获取所有字段值
- hlen key 获取key内的全部field数量
- hexists key field 判断某个key中是否存在field
- hincrby key field number 指定key中的field增加number
- hsetnx key field value 设置key中的field不存在才能保存
## 赋值
bearjun:1>hset hash:demo1 name bearjun
"1"
## 取值
bearjun:1>hget hash:demo1 name
"bearjun"
## 批量赋值
bearjun:1>hmset hash:demo1 age 25 addr hubei
"OK"
## 批量取值
bearjun:1>hmget hash:demo1 name age addr
1) "bearjun"
2) "25"
3) "hubei"
## 获取所有
bearjun:1>hgetall hash:demo1
1) "name"
2) "bearjun"
3) "age"
4) "25"
5) "addr"
6) "hubei"
## 获取指定key的长度
bearjun:1>hlen hash:demo1
"3"
## 判断是否存在
bearjun:1>hexists hash:demo1 name
"1"
bearjun:1>hexists hash:demo2
"ERR wrong number of arguments for 'hexists' command"
bearjun:1>hexists hash:demo2 name
"0"
## 自增
bearjun:1>hincrby hash:demo1 age 1
"26"
## 判断不存在才存入
bearjun:1>hsetnx hash:demo1 name bear
"0"
bearjun:1>hsetnx hash:demo1 play games
"1"
应用场景
- 购物车可以使用hash。
value = 商品的id 、value = 购物的数量 、hlen = 购物的总数 、hgetall = 全选
List
简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。它的底层实际是个双向链表,对两端的操作性能很高,通过索引下标的操作中间的节点性能会较差。

常见用法
- lpush / rpush key value1 value2 value3 .... 从左边/右边插入一个或多个值
- lpop / rpop key 移除最左边 / 右边的一个value,元素在list中删除,返回值为该value
- rpoplpush key1 key2 弹出key1中的最后一个value,并将value插入到key2的末尾,返回值为该value
- lrange key start stop 返回列表key中指定区间内的values,区间以偏移量 start和stop指定。stop为负数则为倒数第几个
- llen key 获得列表长度
- lrem key count value 移除key中指定数量的value。(count = 0 移除所有;count > 0 表头往表尾搜;count < 0 表位往表头搜,count去绝对值)
- lset key index value 将key下标为index的值重新赋值value
- lindex key index 取值key下标为idnex的值
## 从左边插入
bearjun:1>lpush list:demo1 1 2 3 4 5 6
"6"
## 从右边插入
bearjun:1>rpush list:demo2 1 2 3 4 5 6 7 8 9
"9"
## 返回所有的值
bearjun:1>lrange list:demo1 0 -1
1) "6"
2) "5"
3) "4"
4) "3"
5) "2"
6) "1"
bearjun:1>lrange list:demo2 0 -1
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
6) "6"
7) "7"
8) "8"
9) "9"
bearjun:1>lrange list:demo2 0 -2
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
6) "6"
7) "7"
8) "8"
## 查看长度
bearjun:1>llen list:demo1
"6"
bearjun:1>llen list:demo2
"9"
## 将指定的index的赋值
bearjun:1>lset list:demo1 1 1
"OK"
bearjun:1>lset list:demo1 2 1
"OK"
bearjun:1>lset list:demo1 3 1
"OK"
bearjun:1>lrange list:demo1 0 -1
1) "6"
2) "1"
3) "1"
4) "1"
5) "2"
6) "1"
## 返回指定值的index
bearjun:1>lindex list:demo1 2
"1"
bearjun:1>lindex list:demo1 5
"1"
## 取出key1的最右边的值插入key2的最左边
bearjun:1>rpoplpush list:demo1 list:demo2
"1"
bearjun:1>lrange list:demo1 0 -1
1) "6"
2) "1"
3) "1"
4) "1"
5) "2"
bearjun:1>lrange list:demo2 0 -1
1) "1"
2) "1"
3) "2"
4) "3"
5) "4"
6) "5"
7) "6"
8) "7"
9) "8"
10) "9"
## 移除指定数量的值
bearjun:1>lrem list:demo1 -2 1
"2"
bearjun:1>lrange list:demo1 0 -1
1) "6"
2) "1"
3) "2"
应用场景
- 微信订阅号 个人的订阅号可以存在list中,每个vlaue都是订阅号的id
- 列表的收藏 对一个列表中的数据点击收藏,形成一个新的收藏列表
- 轮询 通过rpoplpush反复对一个list轮询处理
Set
Redis set对外提供的功能与list类似是一个列表的功能,特殊之处在于set是可以***自动排重***的,当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的。
Redis的Set是string类型的无序集合。它底层其实是一个value为null的hash表,所以添加,删除,查找的***复杂度都是O(1)***。
常见用法
- sadd key value1 value2 value3 ..... 将一个或多个value元素加入到集合 key 中,已经存在的value元素将被忽略
- smembers key 取出该集合的所有值
- sismember key value 判断集合key是否为含有该value值
- scard key 返回该集合的元素个数
- srem key value1 value2 value3 ..... 删除集合中的value元素
- spop key 移除并返回集合中的一个随机元素
- srandmember key [count] 仅仅返回随机元素,而不对集合进行任何改动;count > 0 返回集合中的元素个数,count < 0 返回可以重复的元素个数
- smove key key2 value 将value从key集合移动到key2集合
- sinter key1 [key2 ....] ** 取指定集合的交集**
- sunion key1 [key2 ....] ** 取指定集合的并集**
- sdiff key1 [key2 ....] ** 取指定集合的差集**
## 赋值
bearjun:1>sadd set:demo1 1 1 2 2 3 3 4 5 6
"6"
## 取值
bearjun:1>smembers set:demo1
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
6) "6"
## 判断是否存在
bearjun:1>sismember set:demo1 7
"0"
bearjun:1>sismember set:demo1 6
"1"
bearjun:1>sismember set:demo 6
"0"
## 数个数
bearjun:1>scard set:demo1
"6"
## 移除某个元素
bearjun:1>srem set:demo1 5 6
"2"
bearjun:1>smembers set:demo1
1) "1"
2) "2"
3) "3"
4) "4"
## 随机取出元素 大于0,不重复最多取整个集合,小于0,取重复的元素
bearjun:1>srandmember set:demo1 2
1) "3"
2) "1"
bearjun:1>srandmember set:demo1 5
1) "1"
2) "2"
3) "3"
4) "4"
bearjun:1>srandmember set:demo1 -5
1) "3"
2) "3"
3) "1"
4) "1"
5) "3"
## 随机弹出一个或多个,并从集合中移除
bearjun:1>spop set:demo1
"3"
bearjun:1>smembers set:demo1
1) "1"
2) "2"
3) "4"
## 把value冲一个集合移入到另一个集合
bearjun:1>smove set:demo1 set:demo2 2
"1"
bearjun:1>smembers set:demo1
1) "1"
2) "4"
bearjun:1>smembers set:demo2
1) "2"
## 取交并差
bearjun:1>sadd set:demo1 1 2 3 4 5 6
"4"
bearjun:1>sadd set:demo2 2 4 6 8
"3"
bearjun:1>smembers set:demo1
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
6) "6"
bearjun:1>smembers set:demo2
1) "2"
2) "4"
3) "6"
4) "8"
bearjun:1>sinter set:demo1 set:demo2
1) "2"
2) "4"
3) "6"
bearjun:1>sdiff set:demo1 set:demo2
1) "1"
2) "3"
3) "5"
bearjun:1>sunion set:demo1 set:demo2
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
6) "6"
7) "8"
应用场景
- 公司年会抽奖 从所有人中取出一个或者多个人
- 社交软件的可能认识的人/共同关注的人等等 通过集合的交集差集可以得出
zSet
Redis有序集合zset与普通集合set非常相似,是一个没有重复元素的字符串集合。
不同之处是有序集合的每个成员都关联了一个***评分(score)***,这个评分(score)被用来按照从最低分到最高分的方式排序集合中的成员。集合的成员是唯一的,但是评分可以是重复了 。
因为元素是有序的, 所以你也可以很快的根据评分(score)或者次序(position)来获取一个范围的元素。
访问有序集合的中间元素也是非常快的,因此你能够使用有序集合作为一个没有重复成员的智能列表。
常见用法
- zadd key score1 value1 [[score2 value2] [score3 value3] ....] 将一个或多个value元素及其score值加入到有序集key当中
- zrange key start stop [withscores] 返回有序集 key 中,下标在start - stop之间的元素,withscores 是否让分数一起返回
- zrangebyscore key min max [withscores] [limit offset count] 返回有序集key中,所有score值介于min和max之间(包括等 min或max)的成员。有序集成员按score值递增(从小到大)次序排列,也可以limit分页查询
- zrevrangebyscore key max min [withscores] [limit offset count] 同上,改为从大到小排列
- zincrby key increment value 为元素的score加上增量
- zrem key value 删除该集合下,指定值的元素
- zcount key min max 统计该集合,分数区间内的元素个数
- zrank key value 返回该值在集合中的排名,从0开始。
## 赋值
bearjun:1>zadd zset:demo1 5000 baidu.com 2600 qq.com 3250 sina.com 10 bearjun.com
"4"
## 查询所有
bearjun:1>zrange zset:demo1 0 -1
1) "bearjun.com"
2) "qq.com"
3) "sina.com"
4) "baidu.com"
bearjun:1>zrange zset:demo1 0 -1 withscores
1) "bearjun.com"
2) "10"
3) "qq.com"
4) "2600"
5) "sina.com"
6) "3250"
7) "baidu.com"
8) "5000"
## 查询分数排序 分页
bearjun:1>zrangebyscore zset:demo1 2000 100000
1) "qq.com"
2) "sina.com"
3) "baidu.com"
bearjun:1>zrangebyscore zset:demo1 2000 100000 limit 0 2
1) "qq.com"
2) "sina.com"
bearjun:1>zrangebyscore zset:demo1 2000 100000 limit 2 4
1) "baidu.com"
bearjun:1>zrevrangebyscore zset:demo1 100000 2000
1) "baidu.com"
2) "sina.com"
3) "qq.com"
## 指定元素分数增加
bearjun:1>zincrby zset:demo1 20 bearjun.com
"30"
bearjun:1>zrange zset:demo1 0 -1
1) "bearjun.com"
2) "qq.com"
3) "sina.com"
4) "baidu.com"
bearjun:1>zrange zset:demo1 0 -1 withscores
1) "bearjun.com"
2) "30"
3) "qq.com"
4) "2600"
5) "sina.com"
6) "3250"
7) "baidu.com"
8) "5000"
## 移除某个元素
bearjun:1>zrem zset:demo1 sina.com
"1"
bearjun:1>zrange zset:demo1 0 -1 withscores
1) "bearjun.com"
2) "30"
3) "qq.com"
4) "2600"
5) "baidu.com"
6) "5000"
## 数指定范围分数的元素个数
bearjun:1>zcount zset:demo1 0 10000000
"3"
bearjun:1>zcount zset:demo1 0 100
"1"
## 查找指定元素在集合中的排序
bearjun:1>zrank zset:demo1 bearjun.com
"0"
应用场景
- 根据商品销售对商品进行排序显示 商品的销量为分数,元素为商品id
- 热搜榜 热度为分数,消息内容为元素
bitMap
位图:用String类型作为底层数据结构实现的一种统计二值状态(true/false)的数据类型。位图本质是数组,它是基于String数据类型的按位的操作。该数组由多个二进制位组成,每个二进制位都对应一个偏移量(我们可以称之为一个索引或者位格)。Bitmap支持的最大位数是232位,它可以极大的节约存储空间,使用512M内存就可以存储多大42.9亿的字节信息(232 = 4294967296)。
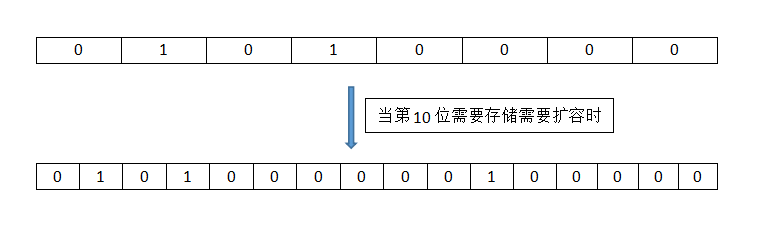
常见用法
- setbit key offset value 对 key所储存的字符串值,设置或清除指定偏移量(offset )上的位(bit)。位的设置或清除取决于value参数,仅为0或者1
- getbit key offset 获取指定偏移量上的位(bit);当offset比字符串值的长度大,或者key不存在时,返回0
- bitcount key [start] [end] 计算给定字符串中,被设置为1的比特位的数量
- bitpos key bit [start] [end] 返回位图中第一个值为bit的二进制位的位置
- bitop operation destkey key [key …] 对一个或多个保存二进制位的字符串key进行位元操作,并将结果保存到destkey上
- BITOP AND destkey key [key ...] ,对一个或多个key求逻辑并,并将结果保存到 destkey
- BITOP OR destkey key [key ...] ,对一个或多个key求逻辑或,并将结果保存到 destkey
- BITOP XOR destkey key [key ...] ,对一个或多个key求逻辑异或,并将结果保存到 destkey
- BITOP NOT destkey key ,对给定 key求逻辑非,并将结果保存到 destkey。
## 设置bit位
bearjun:1>setbit bit:demo1 1 1
"0"
bearjun:1>setbit bit:demo1 2 1
"0"
bearjun:1>setbit bit:demo1 7 1
"0"
## 判断指定位置是的bit
bearjun:1>getbit bit:demo1 1
"1"
bearjun:1>getbit bit:demo1 2
"1"
bearjun:1>getbit bit:demo1 3
"0"
## 数被设置bit的个数
bearjun:1>bitcount bit:demo1
"3"
bearjun:1>bitcount bit:demo1 0 -5
"3"
bearjun:1>bitcount bit:demo1 0 -6
"3"
## 返回第一个被设置bit的位置
bearjun:1>bitpos bit:demo1 1
"1"
bearjun:1>bitpos bit:demo1 0
"0"
## 位元操作
## bit:demo2 = 11001000
bearjun:1>setbit bit:demo2 0 1
"0"
bearjun:1>setbit bit:demo2 1 1
"0"
bearjun:1>setbit bit:demo2 5 1
"0"
## bit:demo3 = 01001000
bearjun:1>setbit bit:demo3 1 1
"0"
bearjun:1>setbit bit:demo3 5 1
"0"
## bit:and = 01001000:对一个或多个key求逻辑并
bearjun:1>bitop and bit:and bit:demo2 bit:demo3
"1"
bearjun:1>getbit bit:and 0
"0"
bearjun:1>getbit bit:and 1
"1"
bearjun:1>getbit bit:and 2
"0"
bearjun:1>getbit bit:and 3
"0"
bearjun:1>getbit bit:and 4
"0"
bearjun:1>getbit bit:and 4
"0"
bearjun:1>getbit bit:and 5
"1"
应用场景
- 统计是否登录,打卡,签到......
- 统计登录,签到的天数,连续天数....
hyperLoglog
HyperLogLog 是一种概率数据结构,用于计算唯一的东西(从技术上讲,这是指估计集合的基数)。通常计算独特的项目需要使用与要计算的项目数量成比例的内存量,因为需要记住过去已经看到的元素,以避免多次计算它们。然而,有一组用内存换取精确度的算法: 以一个标准误差的估计度量结束,在 Redis 实现的情况下,这个误差小于1% 。这个算法的神奇之处在于,不再需要使用与计算的项目数量成比例的内存量,而是可以使用一个恒定的内存量!
一句话概述就是:一种大数据的数据集;可去重,存储空间小,有误差,但不超过1%。
常见用法
- pfadd key element [element …] 将任意数量的元素添加到指定的HyperLogLog里面
- pfcount key [key …] 返回所有给定HyperLogLog的并集的近似基数, 这个近似基数是通过将所有给定HyperLogLog合并至一个临时HyperLogLog来计算得出的
- pfmerge destkey sourcekey [sourcekey …] 将多个HyperLogLog合并(merge)为一个HyperLogLog , 合并后的HyperLogLog的基数接近于所有输入HyperLogLog的可见集合(observed set)的并集。
bearjun:1>pfadd hyper:demo1 bearjun.com baidu.com sina.com qq.com
"1"
bearjun:1>pfcount hyper:demo1
"4"
bearjun:1>pfadd hyper:demo1 bearjun.com
"0"
bearjun:1>pfadd hyper:demo1 google.com
"1"
bearjun:1>pfadd hyper:demo2 youtube.com micosoft.com
"1"
bearjun:1>pfmerge hyper:merge hyper:demo1 hyper:demo2
"OK"
bearjun:1>pfcount hyper:merge
"7"
应用场景
- 网站的访问量UV统计
Geo
Redis Geo主要用于存储地理位置信息。其主要通过经纬度由二维变成一个唯一的点。
常见用法
- geoadd key longitude latitude member [longitude latitude member …] 将给定的空间元素(纬度、经度、名字)添加到指定的键里面。 这些数据会以有序集合的形式被储存在键里面
- geopos key member [member …] 从键里面返回所有给定位置元素的位置(经度和纬度)。
- geodist key member1 member2 [unit] 返回两个给定位置之间的距离。
- georadius key longitude latitude radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [ASC|DESC] [COUNT count] 以给定的经纬度为中心, 返回键包含的位置元素当中, 与中心的距离不超过给定最大距离的所有位置元素。
- georadiusbymember key member radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [ASC|DESC] [COUNT count] 以给定的元素名称为中心, 返回键包含的位置元素当中, 与中心的距离不超过给定最大距离的所有位置元素。
## 存入坐标
bearjun:1>geoadd beijing 116.403766 39.923678 "故宫" 116.417707 39.914382 "王府井" 116.450621 39.921354 "日坛公园" 116.423385 39.908847 "北京同仁医院"
"4"
## 取出坐标
bearjun:1>geopos beijing "故宫" "王府井"
1) 1) "116.40376478433609009"
2) "39.92367692202030582"
2) 1) "116.41770690679550171"
2) "39.91438209952901417"
## 判断距离
bearjun:1>geodist beijing "故宫" "王府井" m
"1575.8560"
bearjun:1>geodist beijing "故宫" "王府井" km
"1.5759"
bearjun:1>georadius beijing 116.417061 39.8882 5 km
1) "北京同仁医院"
2) "故宫"
3) "王府井"
4) "日坛公园"
bearjun:1>georadius beijing 116.417061 39.8882 1 km
bearjun:1>georadius beijing 116.417061 39.8882 2 km
bearjun:1>georadius beijing 116.417061 39.8882 3 km
1) "北京同仁医院"
2) "王府井"
bearjun:1>georadiusbymember beijing "王府井" 3 km
1) "故宫"
2) "王府井"
3) "日坛公园"
4) "北京同仁医院"
## 以上坐标信息来源:http://api.map.baidu.com/lbsapi/getpoint/
## 中国领土完整不容侵犯
应用场景
- 附近的人,附近的酒店,单车等等
- 打卡的时候判断是否到打卡规定的距离范围内
总结
此次只是简单的带大家熟悉和了解redis常用的基本命令和使用场景。后期我们再继续深入讨论。
评论区